Google đọc được tất cả các dữ liệu trên trang web của bạn nhờ quá trình crawl data. Vậy Crawl data là gì? Cách thức hoạt động của các web crawler ra sao? Và nó có tầm ảnh hưởng như thế nào đến quá trình SEO?
Crawl data là gì?
Crawl data là kỹ thuật cào dữ liệu mà các con bobots của Google dùng để thu thập thông tin trên các trang web. Nhiệm vụ của quá trình Crawl Data sau đó là phân tích mã nguồn HTML để đọc dữ liệu. Từ đó lọc ra những thông tin trùng khớp với yêu cầu tìm kiếm của người dùng, giúp công cụ tìm kiếm phân phối các kết quả tìm kiếm đến đúng đối tượng.
Web crawler là gì?
Như vậy, web crawlers là một trình thu thập thông tin có nhiệm vụ download và index toàn bộ content trên không gian mạng. Ngoài Googlebot, còn có nhiều bot crawlers ít phổ biến hơn như Bingbot, Yandex Bot, Baidu Spider… Câu hỏi tiếp theo đặt ra là “Làm thế nào crawler website có thể thu thập và xử lý được hết khối lượng thông tin khổng lồ trên hàng tỷ trang web?” Cùng tìm hiểu nhé!

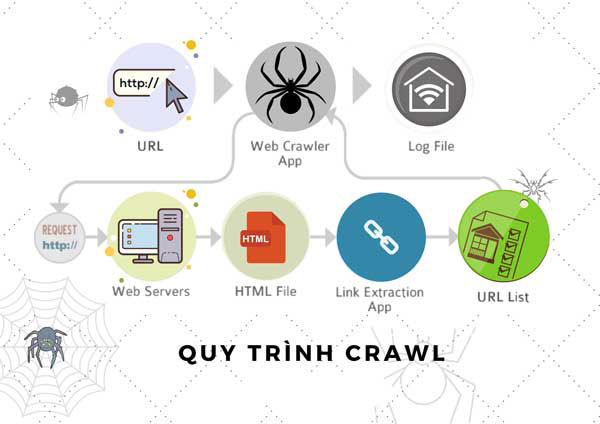
Quy trình crawl data của Google Bot
Từ một danh sách các website đã biết, Google Bots sẽ dựa vào sitemap để lần lượt khám phá và thu thập thông tin trong từng trang trên website.
Tuy nhiên, web crawler sẽ không dò tìm thông tin trên tất cả các trang mà sẽ có sự chọn lọc. Chúng quyết định sẽ thu thập dữ liệu ở trang nào đầu tiên dựa trên 2 tiêu chí chính là: số lượng các liên kết đến trang đó và lượng khách truy cập. Đây là những yếu tố hàng đầu chứng tỏ website chứa thông tin chất lượng cao và có thẩm quyền (EAT). Vì vậy sẽ được công cụ tìm kiếm ưu tiên index trước.
Từ các page này, Google Bots sẽ tìm thấy các siêu liên kết dẫn đến nhiều URL khác. Chúng sẽ lần lượt đi từ liên kết này đến các liên kết có liên quan khác để thu thập tất cả các dữ liệu. Quá trình này sẽ được lặp đi lặp lại nhiều lần. Cho đến khi tất cả các liên kết có liên quan đến nhau được thu thập hết. Đó là cách web crawler thu thập thông tin trên hàng triệu trang khác chỉ từ một trang web ban đầu.
Cuối cùng, các thông tin thu thập được ở hệ thống những trang có liên quan này sẽ được thu thập về máy chủ Google. Google sẽ phân tích và xem xét để xác định chất lượng website và đưa ra quyết định index.
Crawl data ảnh hưởng như thế nào đến SEO?
Mọi SEOer đều mong muốn các nội dung quan trọng trên trang web của mình được Google index một cách nhanh chóng. Chỉ khi đó website mới có cơ hội hiển thị trong các kết quả tìm kiếm và được phân phối đến người dùng tiềm năng. Quá trình Crawl Data là điều kiện tiên quyết để một bài viết được Index trên Google.
Web Crawlers hỗ trợ đắc lực cho quá trình SEO, cụ thể như sau:
- Nâng cao hiệu suất thu thập dữ liệu của Google. Tạo điều kiện để công cụ tìm kiếm hiểu nội dung tốt hơn và lấy được nhiều thông tin nhất trong một lần cào.
- Tiết kiệm thời gian và công sức trong việc thu thập một khối lượng thông tin cực kỳ lớn mà không tốn công nhập liệu.
- Đẩy nhanh quá trình index các trang. Giúp trang web nhanh chóng hiển thị trên trang tìm kiếm, thu về lưu lượng truy cập từ nguồn organic search hoàn toàn miễn phí.

Cách tăng tần suất crawling nội dung quan trọng trên website
Đôi khi vì một lý do nào đó, các nội dung quan trọng trên trang bị che khuất khiến Google Bots không thể tìm thấy để quét dữ liệu. Một số nguyên nhân điển hình là:
- Trang web không có sự đồng nhất giữa điều hướng trên Mobile và Desktop.
- Cá nhân hóa, hoặc điều hướng hiển thị cho một đối tượng khách truy cập cụ thể nào đó.
- Không liên kết đến một trang chính trên website.
- Trang website không có cấu trúc thông tin rõ ràng
Nếu bạn cũng đang gặp những lỗi trên thì cần nhanh chóng khắc phục. Đồng thời cần triển khai một số chiến thuật sau để Google Bots tập trung crawling các nội dung quan trọng trên website:
- Cập nhật nội dung chất lượng thường xuyên lên website, xóa bỏ những nội dung trùng lặp trên trang web.
- Thiết lập file Sitemap.xml cho website.
- Tối ưu tốc độ tải trang, cải thiện tốc độ phản hồi từ server dưới 200ms.
- Nén dung lượng, tối ưu tất cả hình ảnh và video trên trang.
- Tối ưu hệ thống link nội bộ, đồng thời tạo backlink cho website.
- Cân nhắc trong việc cài đặt Search Box trong website. Nếu không cần thiết thì không nên cài đặt.

Cách ngăn Google Crawling nội dung không quan trọng trên Website
Đa số các SEOer chỉ chú ý đến việc làm thế nào để web crawler có thể tìm thấy các trang quan trọng. Nhưng lại quên mất rằng có những nội dung trên website mà bạn không muốn Googlebot tìm thấy.
Bạn chắc hẳn sẽ không muốn Google đọc được những bài viết có nội dung mỏng, trùng lặp; Bài viết copy từ trang web khác; Trang lạm dụng quảng cáo; Hoặc các trang có nội dung đã cũ, thông tin không chính xác… Sau đây là cách để ngăn Google Crawling các dữ liệu không mong muốn này.
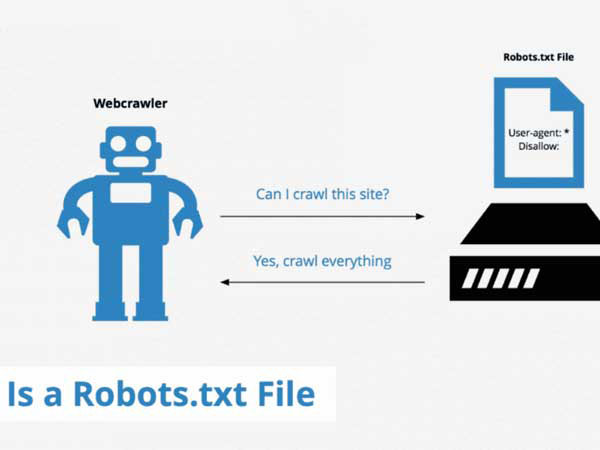
Sử dụng Robots.txt
Robots.txt có khả năng hướng Googlebot ra khỏi các trang và phần nhất định trên trang web. Tệp này sẽ đề xuất cho Google biết phần nào nên và không nên thu thập dữ liệu. Nếu Googlebot tìm thấy tệp Robots.txt trong một trang web, nó thường sẽ tuân theo các đề xuất của Robots.txt. Ngược lại, nếu Google không tin thấy tệp Robots.txt hoặc gặp lỗi khi cố truy cập vào tệp Robots.txt, nó sẽ bỏ qua việc quét dữ liệu trên trang đó.
Tối ưu hóa cho ngân sách thu thập
Ngân sách thu thập (Crawl Budget) là số lượng URL trung bình mà Googlebot sẽ thu thập trên trang web trước khi rời khỏi. Để tối ưu hóa quá trình Crawling Data, hãy đảm bảo chặn trình thu thập nội dung mà bạn chắc chắn không quan trọng. Đồng thời không chặn quyền truy cập của trình thu thập vào các trang bạn đã thêm các chỉ thị khác như “thẻ Canonical” hoặc “Noindex”. Tốt hơn hết là “Noindex” các trang này và không đặt chúng vào tệp Robots.txt.
Xác định tham số URL trong Google Search Console
Sử dụng tính năng “Thêm thông số URL” trong Google Search Console để đề xuất cho Google biết chính xác các trang bạn muốn nó thu thập. Như vậy với những trang không có tham số trong URL thì Google sẽ ngầm hiểu rằng bạn đang yêu cầu ẩn nội dung này khỏi Googlebot.
Trên đây là những thông tin cơ bản về crawl data và cách tối ưu quá trình thu thập dữ liệu trên website của Google. Hãy bắt tay chỉnh sửa và tối ưu SEO ngay hôm nay để website luôn hoạt động hiệu quả với Google Bots.
Tin Tức Liên Quan

Xây dựng chiến lược SEO lên top bền vững không lo update
Google Update là “cơn ác mộng” với tất cả các những người làm SEO. Bởi nó có thể khiến mọi nỗ lực đưa website lên top trước đó sụp đổ hoàn toàn chỉ trong một nốt nhạc

5 sai lầm SEO khi triển khai quy trình đẩy TOP #1
Nếu quy trình SEO của ban lâu nay vẫn cứng nhắc và rập khuôn theo một số gạch đầu dòng nhất định, thì ngay cả những SEOer lâu năm nhất cũng sẽ mắc phải 5 sai lầm phổ biến sau đây.

Top 7 công cụ kiểm tra tốc độ website chính xác nhất
Hiệu suất, tốc độ tải trang chính là một trong những yếu tố quan trọng ảnh hưởng trực tiếp đến trải nghiệm người dùng khi vào website của bạn

Hướng dẫn SEO từ khóa lên top 1 Google nhanh chóng và hiệu quả
Để có thể thu hút nhiều khách hàng truy cập và tương tác với website của mình, doanh nghiệp cần duy trì vị trí trong top tìm kiếm.

Anchor Text là gì? Cách tạo Anchor Text SEO TOP nhanh
Anchor Text giữ một vai trò đặc biệt trong SEO. Tuy nhiên, nhiều SEOer vẫn chưa khám phá được hết công dụng thực sự của nó trong việc tăng hạng website trên Google

Cách xử lý và Disavow Link khi gặp backlink bẩn
Website tốt và chất lượng luôn được xếp hạng cao trên trang tìm kiếm, nhưng không phải lúc nào cũng vậy. Một trong những nguyên nhân dẫn đến việc website bị tụt hạng là do các backlink xấu gây ra

SEO mũ trắng là gì? So sánh SEO mũ trắng và SEO mũ đen
SEO mũ trắng và SEO mũ đen là 2 trường phái đối lập trong lĩnh vực SEO. Và việc lựa chọn sẽ theo trường phái nào luôn là một vấn đề gây tranh cãi trên khắp các diễn đàn
Title tag là gì? Hướng dẫn viết Title giúp tăng CTR website
Tiêu đề (title) là một trong những yếu tố quan trọng quyết định hành động của người dùng tìm kiếm khi tiếp cận một trang web

Phân tích website đối thủ, công cụ nào hiệu quả?
Hiểu chính mình sẽ nắm trong tay 50% cơ hội chiến thắng, hiểu rõ đối thủ sẽ quyết định 50% còn lại. Đó là lý do tại sao việc phân tích website đối thủ lại cực kỳ quan trọng trong SEO




